Feature Engineering
What are features?
Data comes to us in multiple forms – as audio files, images, logs, time series, categories, GPS coordinates, numbers, tweets, text and so on. Most raw data has to be transformed into something usable by algorithms. This ‘something’ represents features.
A feature is a numeric representation of data.
Features are derived from data, and are expressed as numbers.
Feature engineering involves creating the right feature set from available data that is fit-for-purpose for our modeling task (which is to get to the target variable, using other independent variables or attributes).

Feature engineering for numeric data
When raw data is already numeric, it sometimes can be used directly as an input to our models.
However often additional transformations are required to extract useful information from the data. Feature engineering is the process of using domain knowledge to extract features (characteristics, properties, attributes) from raw data. (Source: Wikipedia)
Next, we will discuss common tools available for engineering features from numeric raw data. These are transformations applied to data to convert them into a form that better fits our needs.
What we will cover
- Binning
- Log Transformations
- Box-Cox
- Standardization and Normalization
- Categorical to Numeric
- Imbalanced Data
- Principal Component Analysis
Next, let us launch straight into each of these. We will cover the conceptual ground first, and then demonstrate the idea through code.
Usual library imports first...
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Binning
In binning, we split our data into multiple bins, or buckets, and assign each observation to a limited number of bins. These bin assignments are then used as the feature set.
Consider our diamonds dataset, and the distribution of diamond prices.
Fixed width binning
In fixed width binning, the entire range of observations is divided across a set number of bins.
For example, we could split each diamond into one of 4 equally sized bins.
We can replace the interval notation with labels we assign ourselves.
You can cut the data into a number of fixed bins using pd.qcut. You can specify your own cut-offs for the bins as a list.
Note the interval notation. ( means not-inclusive, and ] means inclusive.
For example:
Assuming integers:
(0, 3) = 1, 2
(0, 3] = 1, 2, 3, 4, 5
[0, 3) = 0, 1, 2
[0, 3] = 0, 1, 2, 3
Load the diamonds dataset
diamonds = sns.load_dataset('diamonds')
print('Shape:',diamonds.shape)
diamonds.sample(4)
Shape: (53940, 10)
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 49506 | 0.71 | Good | E | SI2 | 58.8 | 63.0 | 2120 | 5.75 | 5.88 | 3.42 |
| 38251 | 0.31 | Very Good | J | VS2 | 62.3 | 60.0 | 380 | 4.29 | 4.34 | 2.69 |
| 31157 | 0.41 | Ideal | E | SI1 | 62.6 | 57.0 | 755 | 4.72 | 4.73 | 2.96 |
| 4720 | 0.37 | Ideal | F | SI2 | 60.9 | 56.0 | 572 | 4.65 | 4.68 | 2.84 |
diamonds.price.describe()
count 53940.000000
mean 3932.799722
std 3989.439738
min 326.000000
25% 950.000000
50% 2401.000000
75% 5324.250000
max 18823.000000
Name: price, dtype: float64
diamonds.price.plot(kind='hist', bins = 100, figsize = (10,4), edgecolor='black', title='Diamond Price');
plt.show()
# diamonds.price.plot(kind='hist', bins = 100, figsize = (10,4), logx = True, logy=True, edgecolor='black', title='Log Price');

pd.cut(diamonds.price, bins = 5)
0 (307.503, 4025.4]
1 (307.503, 4025.4]
2 (307.503, 4025.4]
3 (307.503, 4025.4]
4 (307.503, 4025.4]
...
53935 (307.503, 4025.4]
53936 (307.503, 4025.4]
53937 (307.503, 4025.4]
53938 (307.503, 4025.4]
53939 (307.503, 4025.4]
Name: price, Length: 53940, dtype: category
Categories (5, interval[float64, right]): [(307.503, 4025.4] < (4025.4, 7724.8] < (7724.8, 11424.2] < (11424.2, 15123.6] < (15123.6, 18823.0]]
Custom bins
Alternatively, we can use custom bins.
Assume from our domain knowledge we know that diamonds up to \$2,500 are purchased by a certain category of customers, and those that are priced over \$2,500 are targeted at a different category.
We can set up two bins – 0-2500, and 2500-max.
pd.cut(diamonds.price, bins = [0, 2500, 100000])
0 (0, 2500]
1 (0, 2500]
2 (0, 2500]
3 (0, 2500]
4 (0, 2500]
...
53935 (2500, 100000]
53936 (2500, 100000]
53937 (2500, 100000]
53938 (2500, 100000]
53939 (2500, 100000]
Name: price, Length: 53940, dtype: category
Categories (2, interval[int64, right]): [(0, 2500] < (2500, 100000]]
diamonds['pricebin'] = pd.cut(diamonds.price, bins = [0, 2500, 100000])
diamonds[['price', 'pricebin']].sample(6)
| price | pricebin | |
|---|---|---|
| 14258 | 5775 | (2500, 100000] |
| 32100 | 781 | (0, 2500] |
| 51512 | 2384 | (0, 2500] |
| 43692 | 1436 | (0, 2500] |
| 36141 | 928 | (0, 2500] |
| 16990 | 6787 | (2500, 100000] |
# With custom labels
diamonds['pricebin'] = pd.cut(diamonds.price, bins = [0, 2500, 100000], labels=['Low Price', 'High Price'])
diamonds[['price', 'pricebin']].sample(6)
| price | pricebin | |
|---|---|---|
| 27698 | 648 | Low Price |
| 52122 | 2464 | Low Price |
| 44639 | 1609 | Low Price |
| 15978 | 6397 | High Price |
| 25472 | 14240 | High Price |
| 36430 | 942 | Low Price |
diamonds.pricebin.value_counts()
pricebin
Low Price 27542
High Price 26398
Name: count, dtype: int64
Quantile binning
Similar to custom bins – except that we use quantiles to bin the data.
This is useful if the data is skewed and not evenly distributed across its range.
pd.qcut(diamonds.price, 4)
0 (325.999, 950.0]
1 (325.999, 950.0]
2 (325.999, 950.0]
3 (325.999, 950.0]
4 (325.999, 950.0]
...
53935 (2401.0, 5324.25]
53936 (2401.0, 5324.25]
53937 (2401.0, 5324.25]
53938 (2401.0, 5324.25]
53939 (2401.0, 5324.25]
Name: price, Length: 53940, dtype: category
Categories (4, interval[float64, right]): [(325.999, 950.0] < (950.0, 2401.0] < (2401.0, 5324.25] < (5324.25, 18823.0]]
# You can provide label instead of using the default interval notation, and you can
# cut by quartiles using `qcut`
diamonds['pricequantiles'] = pd.qcut(diamonds.price, 4, labels=['Affordale', 'Premium', 'Pricey', 'Expensive'])
diamonds[['price', 'pricequantiles']].sample(6)
| price | pricequantiles | |
|---|---|---|
| 31315 | 758 | Affordale |
| 6043 | 576 | Affordale |
| 14862 | 5987 | Expensive |
| 12234 | 5198 | Pricey |
| 44865 | 1628 | Premium |
| 41990 | 1264 | Premium |
Log transformation
Log transformations are really just the application of the log function to the data. This has the effect of squeezing the big numbers into smaller ones, and the smaller ones into slightly larger ones. The transformation is purely a mathematical trick in the sense we do not lose any information, because we can get back to exactly where we started from by using the anti-log function, more commonly called the exponential.
A primer on logarithms
Log functions are defined such that , where a is a positive constant.We know that , which means .
Taking a log of everything between 0 and 1 yields a negative number, and taking a log of anything greater than 1 yields a positive number.
However, as the number to which the log function is applied, the result increases slowly. The effect of applying the log function is to compress the large numbers, and expand the range of the smaller numbers. The long tail becomes a shorter tail, and the short head becomes a longer head.
Note that this is a mathematical transformation, and we are not losing any information.
We can graph the log function to see this effect.
Note that the exp function is the reverse of the log function.
# graph of the log function - 0 to 10,000.
# log
plt.ylabel('Natural Log of Number')
plt.xlabel('Number')
my_range = np.arange(1e-8,10000, 1)
pd.Series(np.log(my_range), index = my_range).plot.line(figsize = (15,6));

# graph of the log function - 0 to 3
# log
plt.ylabel('Natural Log of Number')
plt.xlabel('Number')
my_range = np.arange(1e-8, 3, .01)
pd.Series(np.log(my_range), index = my_range).plot.line(figsize = (15,6))
plt.hlines(0, 0, 1,linestyles='dashed', colors='red')
plt.vlines(1, -18, 0,linestyles='dashed', colors='red')
plt.yticks(np.arange(-18,3,1))
plt.hlines(1, 0, np.exp(1),linestyles='dotted', colors='green')
plt.vlines(np.exp(1), -18, 1,linestyles='dotted', colors='green')
plt.xticks([0,.5,1,1.5,2,2.5, 2.7182,3]);

print(np.exp(1))
2.718281828459045
One limitation of log transforms is that they can only be applied to positive numbers as logs are not defined for negative numbers.
Log of zero is not defined. If you could end up with log(0), you should add a very tiny number, eg 1e-8 so that you don't end up with a nan.
# Logs of negative numbers, or 0, yield an error
print('Log of 0 is', np.log(0))
print('Log of -1 is', np.log(-1))
print('Log of +1 is', np.log(1))
print('Log of +2.72 is', np.log(2.72))
Log of 0 is -inf
Log of -1 is nan
Log of +1 is 0.0
Log of +2.72 is 1.000631880307906
C:\Users\user\AppData\Local\Temp\ipykernel_2980\4097127657.py:2: RuntimeWarning: divide by zero encountered in log
print('Log of 0 is', np.log(0))
C:\Users\user\AppData\Local\Temp\ipykernel_2980\4097127657.py:3: RuntimeWarning: invalid value encountered in log
print('Log of -1 is', np.log(-1))
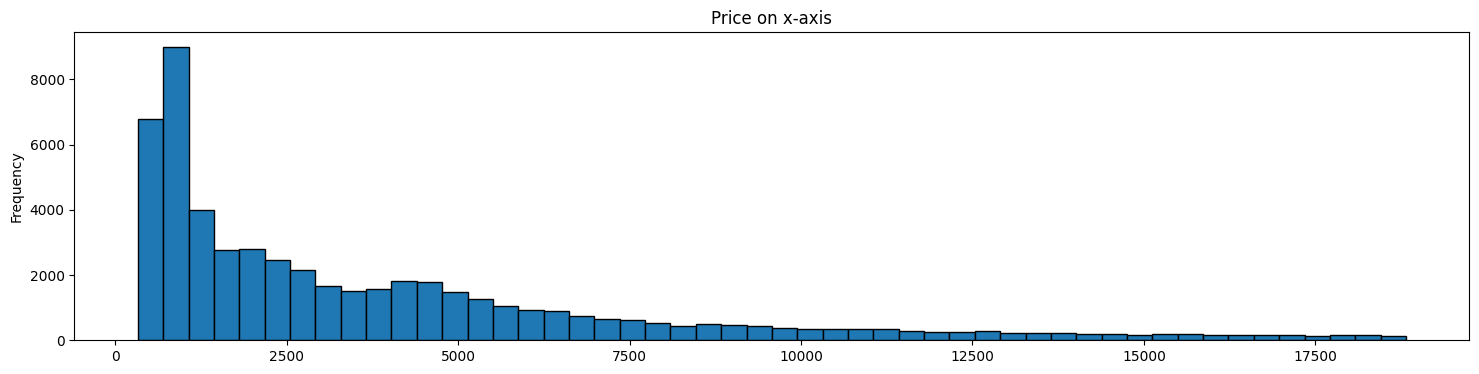
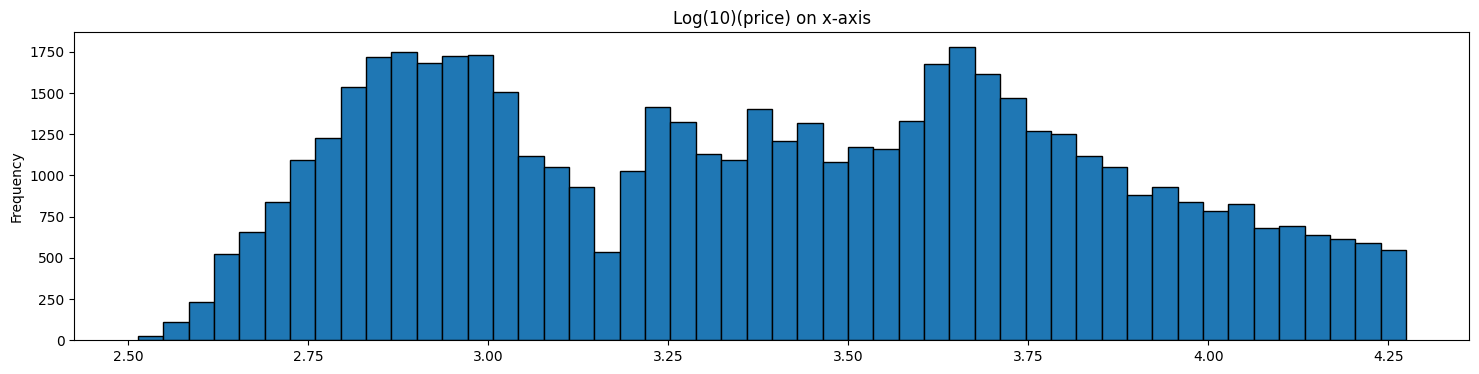
Applying Log Transformation to Price in our Diamonds Dataset
Both graphs below represent the same data.
The second graph represents a ‘feature’ we have extracted from the original data.
In some cases, such transformed data may allow us to build models that perform better.
diamonds.price.plot(kind='hist', bins = 50, figsize = (18,4), \
edgecolor='black', title='Price on x-axis');
plt.show()
diamonds['log_transform'] = np.log10(diamonds.price)
diamonds['log_transform'].plot(kind='hist', bins = 50, figsize = (18,4), \
edgecolor='black', title='Log(10)(price) on x-axis');
Box Cox Transform
The log transform is an example of a family of transformations known as power transforms. In statistical terms, these are variance-stabilizing transformations.
Another similar transform is taking the square root of the data series.
A generalization of the square root transform and the log transform is known as the Box-Cox transform.
The Box-Cox transform takes a parameter, , and its formula is as follows:
If , then: =
If , then: =
When , the Box-Cox transform is nothing but the log transform.
In Python, Box-Cox is available as a function through Scipy. The Scipy implementation optimizes the value of so that the resulting distribution is as close as possible to a normal distribution.
from scipy.stats import boxcox
bc_data, bc_lambda = boxcox(diamonds.price)
print('Lambda is:', bc_lambda)
diamonds['boxcox_transform'] = bc_data
Lambda is: -0.06699030544539092
print('Lambda for Box-Cox is:', bc_lambda)
diamonds.price.plot(kind='hist', bins = 50, figsize = (22,3), edgecolor='black', title='Raw Price data, no transformation');
plt.show()
diamonds['log_transform'].plot(kind='hist', bins = 50, figsize = (22,3), edgecolor='black', title='Log Transform');
plt.show()
diamonds['boxcox_transform'].plot(kind='hist', bins = 50, figsize = (22,3), edgecolor='black', title='Box-Cox Transform');
Lambda for Box-Cox is: -0.06699030544539092



Review the graphics above. The top graph is the untranformed data, the next one is the same data after a log transform, and the final one is the same data after a box-cox transform. Note that it is the x-axis that is being transformed, ie the prices.
The optimal Box-Cox transform deflates the tail more than the log transform. Since the box-cox transform tries to take the distribution as close as possible to a normal distribution, we can use Q-Q plots, or probability plots to compare observed to theoretical quantiles under the normal distribution. For our purposes though, we do not need to do that, so we will skip this.
One limitation of box cox transforms is that they can only be applied to positive numbers. To get over this limitation add a constant equal to the smallest negative value in your data to your entire array.
Feature Scaling
Minmax & standardization
Minmax and standardization of feature columns
The Box-Cox transform handled skew. Sometimes we may need to ‘scale’ the features, which means we make them fit to a nice scale by using simple arithmetic operations.
Min-Max Scaling:
Standardization:
import sklearn.preprocessing as preproc
diamonds['minmax'] = preproc.minmax_scale(diamonds[['price']])
diamonds['standardized'] = preproc.StandardScaler().fit_transform(diamonds[['price']]) # At the column level
diamonds['l2_normalized'] = preproc.normalize(diamonds[['price']], axis=0)
As we can see below, feature scaling did not impact the shape of distribution – only the scaling of the x-axis changed.
Feature scaling is useful when features vary significantly in scale, eg, count of hits of a webpage (large) vs number of orders of the item on that page (very small)
diamonds.price.plot(kind='hist', bins = 50, figsize = (22,2), edgecolor='black', title='Raw Price data, no transformation');
plt.show()
diamonds['minmax'].plot(kind='hist', bins = 50, figsize = (22,2), edgecolor='black', title='Min-Max Scaling');
plt.show()
diamonds['standardized'].plot(kind='hist', bins = 50, figsize = (22,2), edgecolor='black', title='Standardization');
plt.show()
# diamonds['l2_normalized'].plot(kind='hist', bins = 50, figsize = (22,2), edgecolor='black', title='L2 Normalized');
# plt.show()



Using scipy.stats.zscore for a single data series
Standardization of a single data series, or vector can be done using the function zscore.
This may be necessary as StandardScaler expects an m x n array as input (to standardize an entire feature set, as opposed to a single column)
from scipy.stats import zscore
zscore(diamonds.price)
0 -0.904095
1 -0.904095
2 -0.903844
3 -0.902090
4 -0.901839
...
53935 -0.294731
53936 -0.294731
53937 -0.294731
53938 -0.294731
53939 -0.294731
Name: price, Length: 53940, dtype: float64
L2 Normalization
Normalization is the process of scaling individual samples to have unit norm. This process can be useful if you plan to use a quadratic form such as the dot-product or any other kernel to quantify the similarity of any pair of samples. L2 Normalization:
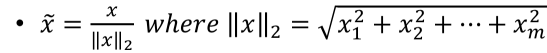
is a constant, equal to the Euclidean length of the vector. is the feature vector itself.
This is useful when observations vary a lot between themselves.
Source: https://scikit-learn.org/stable/modules/preprocessing.html#preprocessing-normalization
Use normalization where observations vary a lot between themselves.
Let us look at an example.
# let us create the dataframe first
# Data source: https://data.worldbank.org/?locations=AU-CN-CH-IN-VN
df = pd.DataFrame({'NI-USDTrillion': {'Australia': 1034.18,
'China': 10198.9,
'India': 2322.05,
'Switzerland': 519.097,
'Vietnam': 176.367},
'AgriLand-sqkm-mm': {'Australia': 3.71837,
'China': 5.285311,
'India': 1.79674,
'Switzerland': 0.01512999,
'Vietnam': 0.121688},
'Freight-mm-ton-km': {'Australia': 1982.586171,
'China': 23323.6147,
'India': 2407.098107,
'Switzerland': 1581.35236,
'Vietnam': 453.34954},
'AirPassengers(m)': {'Australia': 74.257326,
'China': 551.234509,
'India': 139.752424,
'Switzerland': 26.73257,
'Vietnam': 42.592762},
'ArableLandPct': {'Australia': 3.997909522,
'China': 12.67850328,
'India': 52.6088141,
'Switzerland': 10.07651831,
'Vietnam': 22.53781404},
'ArableLandHect': {'Australia': 30.752,
'China': 119.4911,
'India': 156.416,
'Switzerland': 0.398184,
'Vietnam': 6.9883},
'ArmedForces': {'Australia': 58000.0,
'China': 2695000.0,
'India': 3031000.0,
'Switzerland': 21000.0,
'Vietnam': 522000.0}})
df
| NI-USDTrillion | AgriLand-sqkm-mm | Freight-mm-ton-km | AirPassengers(m) | ArableLandPct | ArableLandHect | ArmedForces | |
|---|---|---|---|---|---|---|---|
| Australia | 1034.180 | 3.718370 | 1982.586171 | 74.257326 | 3.997910 | 30.752000 | 58000.0 |
| China | 10198.900 | 5.285311 | 23323.614700 | 551.234509 | 12.678503 | 119.491100 | 2695000.0 |
| India | 2322.050 | 1.796740 | 2407.098107 | 139.752424 | 52.608814 | 156.416000 | 3031000.0 |
| Switzerland | 519.097 | 0.015130 | 1581.352360 | 26.732570 | 10.076518 | 0.398184 | 21000.0 |
| Vietnam | 176.367 | 0.121688 | 453.349540 | 42.592762 | 22.537814 | 6.988300 | 522000.0 |
Consider the dataset above. Some countries have very large numbers compared to the others. Such observations can upset distance and other calculations in our models.
import sklearn.preprocessing as preproc
df2 = pd.DataFrame(preproc.normalize(df), columns = df.columns, index= df.index) # At the row level
df2
| NI-USDTrillion | AgriLand-sqkm-mm | Freight-mm-ton-km | AirPassengers(m) | ArableLandPct | ArableLandHect | ArmedForces | |
|---|---|---|---|---|---|---|---|
| Australia | 0.017817 | 6.406217e-05 | 0.034157 | 0.001279 | 0.000069 | 0.000530 | 0.999257 |
| China | 0.003784 | 1.961067e-06 | 0.008654 | 0.000205 | 0.000005 | 0.000044 | 0.999955 |
| India | 0.000766 | 5.927875e-07 | 0.000794 | 0.000046 | 0.000017 | 0.000052 | 0.999999 |
| Switzerland | 0.024642 | 7.182228e-07 | 0.075067 | 0.001269 | 0.000478 | 0.000019 | 0.996873 |
| Vietnam | 0.000338 | 2.331187e-07 | 0.000868 | 0.000082 | 0.000043 | 0.000013 | 1.000000 |
(df2**2).sum(axis=1)
Australia 1.0
China 1.0
India 1.0
Switzerland 1.0
Vietnam 1.0
dtype: float64
Inversing a transform
The opposite of fit_transform is inverse_transform.
Example: We standardize prices, and reverse the process to get back the original prices.
Normally you will not need to do this as long as the target variable has not been transformed.
diamonds = sns.load_dataset('diamonds')
print('Original diamond prices (first 4 only)')
print(diamonds['price'][:4])
scaler = preproc.StandardScaler()
diamonds['standardized'] = scaler.fit_transform(diamonds[['price']])
print('\n\nStandardized prices')
print(diamonds['standardized'][:4])
print('\n\nReconstructed prices by un-scaling the standardized prices:')
print(scaler.inverse_transform(diamonds['standardized'][:4].values.reshape(-1, 1)))
Original diamond prices (first 4 only)
0 326
1 326
2 327
3 334
Name: price, dtype: int64
Standardized prices
0 -0.904095
1 -0.904095
2 -0.903844
3 -0.902090
Name: standardized, dtype: float64
Reconstructed prices by un-scaling the standardized prices:
[[326.]
[326.]
[327.]
[334.]]
Categorical to Numeric
A lot of data we will encounter as inputs to our modeling process will be categorical, for example, country names, species, gender, county etc. While we humans can make sense of this, algorithms can only consume numerical data. We will next look at a few ways of converting categorical data to numerical information. Conceptually, all of these methods rely on one of two ideas:
- One-hot: Create a separate column for every single category, and populate it with either a 0 or a 1, or
- Label encoding: Call the category values as numbers, eg, High=3, Medium=2, Low=1 etc.
One hot encoding
- Categorical variables represent categories, or labels.
- Cardinal/Nonordinal categories: For example, names of species, countries, industry, gender etc. No natural order, and < or > relationships do not apply
- Ordinal categories: For example, High, Medium, Low (where High > Medium > Low), or XL, L, M, S
- Most ML/AI algorithms cannot deal with categorical variables on their own, and require categories to be converted to numerical arrays.
- One-hot encoding is often used to convert categories to numbers.
- Variations include dropping the first category, and effect encoding.
One hot encoding creates a column with a 1 or 0 for each category label.
df = pd.DataFrame({'fruit':
['apple', 'banana', 'pear',
'pear', 'apple', 'apple'],
'weight_gm':[120,100,104,60,98,119],
'price':[0.25, 0.18, 0.87, 0.09, 1.02,.63]})
df
| fruit | weight_gm | price | |
|---|---|---|---|
| 0 | apple | 120 | 0.25 |
| 1 | banana | 100 | 0.18 |
| 2 | pear | 104 | 0.87 |
| 3 | pear | 60 | 0.09 |
| 4 | apple | 98 | 1.02 |
| 5 | apple | 119 | 0.63 |
pd.get_dummies(df)
| weight_gm | price | fruit_apple | fruit_banana | fruit_pear | |
|---|---|---|---|---|---|
| 0 | 120 | 0.25 | True | False | False |
| 1 | 100 | 0.18 | False | True | False |
| 2 | 104 | 0.87 | False | False | True |
| 3 | 60 | 0.09 | False | False | True |
| 4 | 98 | 1.02 | True | False | False |
| 5 | 119 | 0.63 | True | False | False |
You only really need columns to encode categories. The all-zeros vector represents the first category, called in this case the ‘reference category’.
One hot encoding can be challenging to use if there are more than a handful of categories. We can do this in pandas using the parameter drop_first=True.
pd.get_dummies(df, drop_first=True)
| weight_gm | price | fruit_banana | fruit_pear | |
|---|---|---|---|---|
| 0 | 120 | 0.25 | False | False |
| 1 | 100 | 0.18 | True | False |
| 2 | 104 | 0.87 | False | True |
| 3 | 60 | 0.09 | False | True |
| 4 | 98 | 1.02 | False | False |
| 5 | 119 | 0.63 | False | False |
Label encoding
What we saw with get_dummies would work for input variables (as most models will accommodate more columns), but how do we deal with target variables that are categorical?
This can become an issue as most ML algorithms expect a single column target variable.
In such situations, we can assign numbers to different categories, eg,
0 = apple,
1 = banana,
2 = pear etc.!
Original data is transformed into labels that are classes named as 0, 1
df
| fruit | weight_gm | price | |
|---|---|---|---|
| 0 | apple | 120 | 0.25 |
| 1 | banana | 100 | 0.18 |
| 2 | pear | 104 | 0.87 |
| 3 | pear | 60 | 0.09 |
| 4 | apple | 98 | 1.02 |
| 5 | apple | 119 | 0.63 |
For multiclass classification problems for neural nets, a slightly different label encoding scheme is desired.
We use tensorflow’s to_categorical function on the encoded labels (not on the raw labels!). The function converts a class vector (integers) to binary class matrix.
This is similar to get_dummies() from pandas.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
encoded_labels = le.fit_transform(df['fruit'].values.ravel()) # This needs a 1D array
df['encoded_labels'] = encoded_labels
df
| fruit | weight_gm | price | encoded_labels | |
|---|---|---|---|---|
| 0 | apple | 120 | 0.25 | 0 |
| 1 | banana | 100 | 0.18 | 1 |
| 2 | pear | 104 | 0.87 | 2 |
| 3 | pear | 60 | 0.09 | 2 |
| 4 | apple | 98 | 1.02 | 0 |
| 5 | apple | 119 | 0.63 | 0 |
# Enumerate Encoded Classes
dict(list(enumerate(le.classes_)))
{0: 'apple', 1: 'banana', 2: 'pear'}
from tensorflow.keras.utils import to_categorical
to_categorical(encoded_labels)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[1., 0., 0.],
[1., 0., 0.]], dtype=float32)
Next, we look at some of the commonly used functions used for converting categories to numbers.
OneHotEncoder
Used for X variables. Can convert multiple columns to one hot format directly from categorical text. Directly takes an array as an input.
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
values = df[['fruit']]
values
| fruit | |
|---|---|
| 0 | apple |
| 1 | banana |
| 2 | pear |
| 3 | pear |
| 4 | apple |
| 5 | apple |
oh = OneHotEncoder(sparse_output=False)
myonehot = oh.fit_transform(values)
myonehot
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[1., 0., 0.],
[1., 0., 0.]])
LabelEncoder
Used for Y variables - this doesn't give you one-hot encoding, but gives you integer encoding.
le = LabelEncoder()
int = le.fit_transform(values.fruit.ravel()) # This needs a 1D arrary
print("Now int has integers, type is ", type(int))
print('int shape: ', int.shape)
int
Now int has integers, type is <class 'numpy.ndarray'>
int shape: (6,)
array([0, 1, 2, 2, 0, 0])
LabelBinarizer
Used for Y variables - produces one-hot encoding for Y variables. Each observation belongs to one and only one class.
lb = LabelBinarizer()
myonehot = lb.fit_transform(values)
my1hot_df = pd.DataFrame(lb.fit_transform(values), columns=lb.classes_)
print(my1hot_df)
print('\n \n')
print(myonehot)
apple banana pear
0 1 0 0
1 0 1 0
2 0 0 1
3 0 0 1
4 1 0 0
5 1 0 0
[[1 0 0]
[0 1 0]
[0 0 1]
[0 0 1]
[1 0 0]
[1 0 0]]
MultiLabelBinarizer: This is used when an observation can belong to multiple labels
df = pd.DataFrame({"genre": [["action", "drama","fantasy"], \
["fantasy","action"], ["drama"],
["sci-fi", "drama"]]})
df
| genre | |
|---|---|
| 0 | [action, drama, fantasy] |
| 1 | [fantasy, action] |
| 2 | [drama] |
| 3 | [sci-fi, drama] |
mlb = MultiLabelBinarizer()
myonehot = mlb.fit_transform(df['genre'])
my1hot_df = pd.DataFrame(mlb.fit_transform(df['genre']), columns=mlb.classes_)
print('mlb.classes \n',mlb.classes_, '\n\n')
print('my1hot_df \n', my1hot_df, '\n\n')
print('myonehot \n', myonehot, '\n\n')
mlb.classes
['action' 'drama' 'fantasy' 'sci-fi']
my1hot_df
action drama fantasy sci-fi
0 1 1 1 0
1 1 0 1 0
2 0 1 0 0
3 0 1 0 1
myonehot
[[1 1 1 0]
[1 0 1 0]
[0 1 0 0]
[0 1 0 1]]
Imbalanced classes
Imbalanced data is data for classification problems where the observations are not equally distributed (or roughly so) across the different classes. An imbalanced data set is one with skewed class proportions.
As a result, many algorithms underperform as they do not get to learn the underrepresented class, which is often the one of interest.
Example: a dataset for disease prediction has <1% of the observations which are positive for the disease.
There is no precise definition of when a dataset should be considered imbalanced, but as a rule of thumb it is something to be concerned about if less than 20% of the observations belong to one class in a binary classification problem.
Approaches to addressing the problem of imbalanced data focus on doing something that improves the ratio of the underrepresented category in the dataset.
This can be done in two ways:
- Reduce observations in the majority class
- Increase observations for the minority class
Let us see next how this can be done.
Old Faithful Dataset
We look at the dataset from the Old Faithful geyser's eruptions at the Yellowstone National Park.
Data Description: - Waiting time between eruptions and the duration of the eruption for the Old Faithful geyser in Yellowstone National Park, Wyoming, USA.
- A data frame with 272 observations on 2 variables.
Columns:
- duration - numeric - Eruption time in mins
- waiting - numeric - Waiting time to next eruption
- kind - categorical - Kind of eruption (long/short)
df = sns.load_dataset('geyser')
df
| duration | waiting | kind | |
|---|---|---|---|
| 0 | 3.600 | 79 | long |
| 1 | 1.800 | 54 | short |
| 2 | 3.333 | 74 | long |
| 3 | 2.283 | 62 | short |
| 4 | 4.533 | 85 | long |
| ... | ... | ... | ... |
| 267 | 4.117 | 81 | long |
| 268 | 2.150 | 46 | short |
| 269 | 4.417 | 90 | long |
| 270 | 1.817 | 46 | short |
| 271 | 4.467 | 74 | long |
272 rows × 3 columns
print(df.kind.value_counts())
print('\n---\n')
print(df.kind.value_counts(normalize=True))
kind
long 172
short 100
Name: count, dtype: int64
---
kind
long 0.632353
short 0.367647
Name: proportion, dtype: float64
# Split the dataframe between X and y
X = df[['duration', 'waiting']]
y = df[['kind']]
y.value_counts()
kind
long 172
short 100
Name: count, dtype: int64
Approach 1: Reduce Observations for Majority Class
Several approaches available, for example:
- Random Under Sampling: Randomly remove majority class observations to match the number of observations in the minority class.
- Cluster Centroids Method: Remove majority class observations and replace them with synthetic data representing the centroids of k-means clusters.
Observations are removed till all classes have a count of observation equal to the class with the lowest count of observations.
Generally, 1 above (random undersampling) should suffice for most general cases. Other approaches available as well, listed at https://imbalanced-learn.org/
Random Under Sampler
Several approaches available, for example:
- Random Under Sampling: Randomly remove majority class observations to match the number of observations in the minority class.
- Cluster Centroids Method: Remove majority class observations and replace them with synthetic data representing the centroids of k-means clusters.
Observations are removed till all classes have a count of observation equal to the class with the lowest count of observations.
Generally, 1 above (random undersampling) should suffice for most general cases.
Other approaches available as well, listed at https://imbalanced-learn.org/
from imblearn.under_sampling import RandomUnderSampler
undersampler = RandomUnderSampler()
X_res, y_res = undersampler.fit_resample(X, y)
y_res.value_counts()
kind
long 100
short 100
Name: count, dtype: int64
X
| duration | waiting | |
|---|---|---|
| 0 | 3.600 | 79 |
| 1 | 1.800 | 54 |
| 2 | 3.333 | 74 |
| 3 | 2.283 | 62 |
| 4 | 4.533 | 85 |
| ... | ... | ... |
| 267 | 4.117 | 81 |
| 268 | 2.150 | 46 |
| 269 | 4.417 | 90 |
| 270 | 1.817 | 46 |
| 271 | 4.467 | 74 |
272 rows × 2 columns
y
| kind | |
|---|---|
| 0 | long |
| 1 | short |
| 2 | long |
| 3 | short |
| 4 | long |
| ... | ... |
| 267 | long |
| 268 | short |
| 269 | long |
| 270 | short |
| 271 | long |
272 rows × 1 columns
Centroid Based Under Sampler
from imblearn.under_sampling import ClusterCentroids
clustercentroids = ClusterCentroids()
X_res, y_res = clustercentroids.fit_resample(X, y)
C:\Users\user\AppData\Local\Programs\Python\Python310\lib\site-packages\sklearn\cluster\_kmeans.py:1416: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
super()._check_params_vs_input(X, default_n_init=10)
y_res.value_counts()
kind
long 100
short 100
Name: count, dtype: int64
Notice how the majority class has been undersampled to match the count of 100 short eruptions (the minority class).
Approach 2: Add Observations to the Minority Classes
Several approaches available, for example:
- Random Over Sampling: Randomly duplicate observations in the minority class till the count of the modal class is reached
- SMOTE: Synthetic Minority Oversampling Technique
You may have to try both approaches to see which one gives you better results.
All classes that have observations fewer than the class with the maximum count will have their counts increased to match that of the class with the highest count.
Random Over Sampler
from imblearn.over_sampling import RandomOverSampler
randomoversampler = RandomOverSampler()
X_res, y_res = randomoversampler.fit_resample(X, y)
y_res.value_counts()
kind
long 172
short 172
Name: count, dtype: int64
SMOTE Over Sampler
SMOTE = Synthetic Minority Oversampling Technique
SMOTE works as follows:
1. Take a random sample from the minority class
2. Find k nearest neighbors for this sample observation
3. Randomly select one of the neighbors
4. Draw a line between this random neighbor and the sample observation
5. Identify a point on the line between the two to get another minority data point.
Fortunately, this complicated series of motions is implemented for us in Python by the library imbalanced-learn
Often, under-sampling and SMOTE are combined to build a larger data set with greater representation for the minority class.
from imblearn.over_sampling import SMOTE
smote = SMOTE()
X_res, y_res = smote.fit_resample(X, y)
y_res.value_counts()
kind
long 172
short 172
Name: count, dtype: int64
Notice how the count of observations in the minority class have gone up to match the count of the majority class.
Principal Component Analysis
Overview
The problem we are trying to solve with PCA is that when we are trying to look for relationships in data, there may sometimes be too many variables in the feature set that are all somewhat related to each other.
Consider the mtcars dataset. Though the columns represent different things, we can imagine that horsepower, number of cylinders, engine size (displacement) etc are all related to each other.
What PCA allows us to do is to replace a large number of variables with much fewer ‘artificial’ variables that effectively represent the same data. These artificial variables are called principal components.
So you might have a hundred variables in the original data set, and you may be able to replace them with just two or three mathematically constructed ‘artificial variables’ that explain the data just about as well as the original data set.
These ‘artificial variables’ are built mathematically as linear combinations of the underlying original variables. These new ‘artificial variables’, called principal components, may or may not be capable of any intuitive human interpretation.
The number of principal components that can be identified for any dataset is equal to the number of the variables in the dataset. But if one had to use all the principal components, it would not be very helpful because the complexity of the data is not reduced at all, and we are replacing natural variables with artificial ones that may not have a logical interpretation.
We can decide which principal components to use and which to discard. But how do we do that?
Each principal component accounts for a part of the total variation that the original dataset had. We pick the top 2 or 3 (or n) principal components so we have a satisfactory proportion of the variation in the original dataset.
What does ‘variation’ mean, you might ask.
Think of the data set as a scatterplot. If we had two variables, think about how they would look when plotted on a scatter plot. If we had three variables, try to visualize a three dimensional plane and how the data points would look – like a cloud kind of clustering together a little bit (or not) depending upon how correlated the system is.
The ‘spread’ of this cloud is really the ‘variation’ contained in the data set. This can be measured in the form of variance, with each of the n columns having a variance.
Once the principal components for the feature data have been calculated, we can also calculate the variance for each of the principal components.
Fortunately, the simple summation of the variance of the individual original variables is equal to the summation of the variances of the principal components. But it is distributed differently.
We arrange the principal components in descending order of the variance each of them explains, take the top few principal components, add up their variance, and compare it to the total variance to determine how much of the variance is accounted for. If we have enough to meet our needs, we stop there.
For example, if the top 3 or 4 principal components explain 90% of the variance (not unusual), we might just take those as our new features to replace our old cumbersome 100-column feature set, greatly simplifying our modeling problem.
PCA in Practice - Steps
1. PCA begins with standardizing the feature set.
2. Then we calculate the covariance matrix (which after standardization is the same as the correlation matrix).
3. For this covariance matrix, we now calculate the eigenvectors and eigenvalues.
4. Every eigenvector would have as many elements as the number of features in the original dataset. These elements represent the ‘weights’ for the linear combination of the different features.
5. The eigenvalues for each of the eigenvectors represent the amount of variance that the given eigenvector accounts for. We arrange the eigenvectors in decreasing order of the eigenvalues, and pick the top 2, 3 (or as many eigenvalues) that we are interested in depending upon how much variance we want to capture in our model.
6. If we include all the eigenvectors, then we would have captured all the variance but this would not give us any advantage over our initial data.
7. In a simplistic way, that is about all that there is to PCA. Fortunately for us, all of this is already implemented in statistical libraries, and as practitioners we need to know only the intuition before we apply it.
# Load the mtcars data
import statsmodels.api as sm
df = sm.datasets.get_rdataset('mtcars').data
print('Dataframe shape: ',df.shape)
df.head()
Dataframe shape: (32, 11)
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| rownames | |||||||||||
| Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360.0 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
We run principal component analysis on the mtcars dataset. We target capturing 80% of the variation in the dataset. We see that just two principal components capture 84% of the variation observed in the original 10 feature dataset.
# Separate out the features (assuming mpg is the target variable)
feat = df.iloc[:,1:]
# Next, standard scale the feature set
import sklearn.preprocessing as preproc
feat = pd.DataFrame(data=preproc.StandardScaler().fit_transform(feat), columns=feat.columns, index = feat.index)
print(feat.shape)
feat.head()
(32, 10)
| cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|
| rownames | ||||||||||
| Mazda RX4 | -0.106668 | -0.579750 | -0.543655 | 0.576594 | -0.620167 | -0.789601 | -0.881917 | 1.208941 | 0.430331 | 0.746967 |
| Mazda RX4 Wag | -0.106668 | -0.579750 | -0.543655 | 0.576594 | -0.355382 | -0.471202 | -0.881917 | 1.208941 | 0.430331 | 0.746967 |
| Datsun 710 | -1.244457 | -1.006026 | -0.795570 | 0.481584 | -0.931678 | 0.432823 | 1.133893 | 1.208941 | 0.430331 | -1.140108 |
| Hornet 4 Drive | -0.106668 | 0.223615 | -0.543655 | -0.981576 | -0.002336 | 0.904736 | 1.133893 | -0.827170 | -0.946729 | -1.140108 |
| Hornet Sportabout | 1.031121 | 1.059772 | 0.419550 | -0.848562 | 0.231297 | -0.471202 | -0.881917 | -0.827170 | -0.946729 | -0.511083 |
# Check out the correlation
sns.heatmap(feat.corr(numeric_only=True), annot=True);
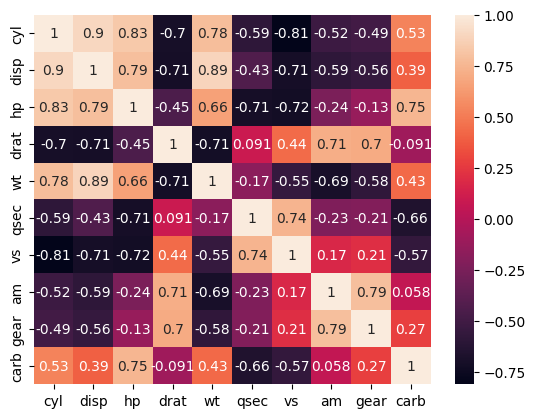
Consider the mtcars dataset above. Though the columns represent different things, we can imagine that horsepower, number of cylinders, engine size (displacement) etc are all related to each other.
We run principal component analysis on the mtcars dataset. We target capturing 80% of the variation in the dataset. We see below that just two principal components capture 84% of the variation observed in the original 10 feature dataset.
Principal Components
from sklearn.decomposition import PCA
pca = PCA(n_components=.8) #0.8 means keep 80% of the variance
# Get the new features and hold them in variable new
pc_mtcars = pca.fit_transform(feat)
pc_mtcars.shape
(32, 10)
pc_mtcars = pd.DataFrame(pc_mtcars)
pc_mtcars
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.632134 | 1.739877 | -0.665110 | 0.100862 | -0.927621 | 0.051528 | -0.400939 | -0.177965 | -0.067495 | -0.163161 |
| 1 | 0.605027 | 1.554343 | -0.434619 | 0.190621 | -1.033729 | -0.156044 | -0.421950 | -0.085054 | -0.125251 | -0.071543 |
| 2 | 2.801549 | -0.122632 | -0.414510 | -0.263449 | 0.446730 | -0.507376 | -0.291290 | -0.084116 | 0.162350 | 0.181756 |
| 3 | 0.259204 | -2.364265 | -0.095090 | -0.505929 | 0.552199 | -0.035541 | -0.058233 | -0.188187 | -0.101924 | -0.166531 |
| 4 | -2.032508 | -0.774822 | -1.016381 | 0.081071 | 0.200412 | 0.163234 | 0.285340 | 0.116682 | -0.108244 | -0.181168 |
| 5 | 0.204867 | -2.778790 | 0.093328 | -0.995552 | 0.227545 | -0.323183 | -0.150440 | -0.045932 | -0.154474 | 0.033869 |
| 6 | -2.846324 | 0.318210 | -0.324108 | -0.053138 | 0.423729 | 0.686200 | -0.201259 | 0.179319 | 0.362386 | -0.195036 |
| 7 | 1.938647 | -1.454239 | 0.955656 | -0.138849 | -0.349183 | 0.073207 | 0.641096 | -0.374506 | 0.239646 | -0.031233 |
| 8 | 2.300271 | -1.963602 | 1.751220 | 0.299541 | -0.408112 | -0.255902 | 0.542837 | 0.935339 | -0.061213 | -0.130912 |
| 9 | 0.636986 | -0.150858 | 1.434045 | 0.066155 | 0.010042 | 0.845973 | 0.168722 | -0.543588 | -0.260493 | 0.124549 |
| 10 | 0.712003 | -0.308009 | 1.571549 | 0.090629 | -0.062764 | 0.746137 | 0.155767 | -0.340193 | -0.343927 | 0.071815 |
| 11 | -2.168500 | -0.698349 | -0.318649 | -0.132449 | -0.380210 | 0.193121 | -0.104051 | 0.091823 | -0.060831 | 0.389843 |
| 12 | -2.013998 | -0.698920 | -0.409019 | -0.213513 | -0.353604 | 0.312365 | -0.096477 | 0.288854 | -0.115464 | 0.184484 |
| 13 | -1.983030 | -0.811307 | -0.297320 | -0.184076 | -0.409623 | 0.223378 | -0.106863 | 0.405446 | -0.167143 | 0.176943 |
| 14 | -3.540037 | -0.841191 | 0.646830 | 0.299781 | -0.144468 | -0.895457 | -0.091503 | -0.234988 | 0.052358 | -0.258041 |
| 15 | -3.597893 | -0.747153 | 0.725851 | 0.417433 | -0.092404 | -0.875780 | -0.121889 | -0.248904 | 0.121949 | -0.036876 |
| 16 | -3.493731 | -0.445347 | 0.702793 | 0.696399 | 0.074896 | -0.605711 | -0.147697 | -0.182902 | 0.201483 | 0.145296 |
| 17 | 3.329571 | -0.292943 | -0.277423 | 0.073323 | 0.112670 | -0.421673 | -0.305017 | 0.070160 | -0.116413 | 0.129409 |
| 18 | 3.883988 | 0.704290 | -0.202656 | 1.186911 | 0.133843 | 0.540753 | -0.410649 | -0.133756 | -0.228625 | -0.282043 |
| 19 | 3.636227 | -0.276133 | -0.292044 | 0.206366 | 0.113590 | -0.245487 | -0.304007 | 0.365579 | -0.231154 | -0.056534 |
| 20 | 1.962264 | -2.101797 | 0.030140 | 0.037593 | 0.162210 | 0.672144 | -0.164937 | 0.306503 | 0.606158 | -0.031204 |
| 21 | -2.048033 | -1.026281 | -1.177374 | -0.604969 | -0.181947 | 0.089924 | 0.225311 | -0.162343 | -0.117839 | -0.019935 |
| 22 | -1.682576 | -0.913388 | -1.014237 | -0.008073 | -0.183926 | 0.270837 | 0.220226 | 0.061937 | -0.246339 | 0.014154 |
| 23 | -2.658623 | 0.669277 | -0.184127 | 0.821191 | 0.509528 | 0.897013 | -0.185740 | -0.017670 | 0.359389 | 0.101728 |
| 24 | -2.354816 | -0.899123 | -0.869987 | 0.161906 | 0.233469 | -0.171734 | 0.331052 | -0.079515 | -0.075497 | -0.191597 |
| 25 | 3.358263 | -0.103399 | -0.514251 | -0.018818 | 0.222321 | -0.208830 | -0.282955 | -0.022693 | -0.058105 | 0.031465 |
| 26 | 2.440051 | 2.057439 | -0.881101 | 0.568156 | -0.621810 | -0.300175 | 1.030298 | 0.014321 | 0.403521 | 0.121686 |
| 27 | 2.946328 | 1.383718 | -0.355847 | -1.159294 | 0.678108 | -0.024936 | 0.467431 | -0.239450 | 0.166930 | -0.100088 |
| 28 | -1.212566 | 3.498277 | -0.197467 | 0.600021 | 1.124186 | -0.342886 | 0.664866 | 0.153216 | -0.426021 | 0.129397 |
| 29 | 0.014182 | 3.221361 | 0.374340 | -0.959536 | -0.853213 | 0.081124 | 0.024243 | -0.114836 | 0.137882 | -0.052590 |
| 30 | -2.541137 | 4.366990 | 1.428770 | -0.874904 | 0.415883 | -0.011549 | -0.409474 | 0.456812 | 0.026336 | -0.091492 |
| 31 | 2.512210 | 0.258768 | 0.226798 | 0.214592 | 0.361254 | -0.464676 | -0.501820 | -0.169392 | 0.226064 | 0.223587 |
# proportion variance explained by each of the principal components
pca.explained_variance_ratio_
array([0.57602174, 0.26496432, 0.05972149, 0.02695067, 0.02222501,
0.02101174, 0.01329201, 0.00806816, 0.00536523, 0.00237963])
# proportion variance explained by including each PC
(pca.explained_variance_ratio_).cumsum()
array([0.57602174, 0.84098606])
# proportion variance explained by both
(pca.explained_variance_ratio_).cumsum()[-1]
0.8409860622774867
# Absolute variance explained
pca.explained_variance_
array([5.9460309 , 2.73511555])
# Check if the principal components are orthogonal (dot product should be zero)
np.dot(pc_mtcars[0], pc_mtcars[1])
4.440892098500626e-15
pc_mtcars.head()
| 0 | 1 | |
|---|---|---|
| 0 | 0.632134 | 1.739877 |
| 1 | 0.605027 | 1.554343 |
| 2 | 2.801549 | -0.122632 |
| 3 | 0.259204 | -2.364265 |
| 4 | -2.032508 | -0.774822 |
pc_mtcars.index = df.index
pc_mtcars.columns = ['PC-0', 'PC-1']
pc_mtcars
| PC-0 | PC-1 | |
|---|---|---|
| rownames | ||
| Mazda RX4 | 0.632134 | 1.739877 |
| Mazda RX4 Wag | 0.605027 | 1.554343 |
| Datsun 710 | 2.801549 | -0.122632 |
| Hornet 4 Drive | 0.259204 | -2.364265 |
| Hornet Sportabout | -2.032508 | -0.774822 |
| Valiant | 0.204867 | -2.778790 |
| Duster 360 | -2.846324 | 0.318210 |
| Merc 240D | 1.938647 | -1.454239 |
| Merc 230 | 2.300271 | -1.963602 |
| Merc 280 | 0.636986 | -0.150858 |
| Merc 280C | 0.712003 | -0.308009 |
| Merc 450SE | -2.168500 | -0.698349 |
| Merc 450SL | -2.013998 | -0.698920 |
| Merc 450SLC | -1.983030 | -0.811307 |
| Cadillac Fleetwood | -3.540037 | -0.841191 |
| Lincoln Continental | -3.597893 | -0.747153 |
| Chrysler Imperial | -3.493731 | -0.445347 |
| Fiat 128 | 3.329571 | -0.292943 |
| Honda Civic | 3.883988 | 0.704290 |
| Toyota Corolla | 3.636227 | -0.276133 |
| Toyota Corona | 1.962264 | -2.101797 |
| Dodge Challenger | -2.048033 | -1.026281 |
| AMC Javelin | -1.682576 | -0.913388 |
| Camaro Z28 | -2.658623 | 0.669277 |
| Pontiac Firebird | -2.354816 | -0.899123 |
| Fiat X1-9 | 3.358263 | -0.103399 |
| Porsche 914-2 | 2.440051 | 2.057439 |
| Lotus Europa | 2.946328 | 1.383718 |
| Ford Pantera L | -1.212566 | 3.498277 |
| Ferrari Dino | 0.014182 | 3.221361 |
| Maserati Bora | -2.541137 | 4.366990 |
| Volvo 142E | 2.512210 | 0.258768 |
plt.figure(figsize = (8,8))
x, y = pc_mtcars['PC-0'].values, pc_mtcars['PC-1'].values
ax = plt.scatter(x,y)
for i, txt in enumerate(pc_mtcars.index):
plt.annotate(txt, (x[i], y[i]), fontsize=10)

Eigenvectors
Check if eigenvectors multiplied by original feature set data equals the principal components (Optional)
# Eigenvectors. These are multiplied by the actual features and summed up to get the new features
ev = pca.components_
ev
array([[-0.40297112, -0.39592428, -0.35432552, 0.3155948 , -0.36680043,
0.21989818, 0.33335709, 0.24749911, 0.22143747, -0.22670801],
[ 0.03901479, -0.05393117, 0.24496137, 0.27847781, -0.14675805,
-0.46066271, -0.22751987, 0.43201042, 0.46516217, 0.411693 ]])
# For the first observation, these are the new feature values
pc_mtcars.iloc[0:2]
| PC-0 | PC-1 | |
|---|---|---|
| rownames | ||
| Mazda RX4 | 0.632134 | 1.739877 |
| Mazda RX4 Wag | 0.605027 | 1.554343 |
# Original standardized features for the first observation
feat.iloc[0]
cyl -0.106668
disp -0.579750
hp -0.543655
drat 0.576594
wt -0.620167
qsec -0.789601
vs -0.881917
am 1.208941
gear 0.430331
carb 0.746967
Name: Mazda RX4, dtype: float64
# Multiplying the first observation with the eignevectors
(ev[0] * feat.iloc[0])
cyl 0.042984
disp 0.229537
hp 0.192631
drat 0.181970
wt 0.227477
qsec -0.173632
vs -0.293993
am 0.299212
gear 0.095292
carb -0.169343
Name: Mazda RX4, dtype: float64
# Next we sum up the above to get the first PC for the first observation
(ev[0] * feat.iloc[0]).sum()
0.6321344928989641
# We can get the first PC for all the observations together as well
(ev[0] * feat).sum(axis=1)
rownames
Mazda RX4 0.632134
Mazda RX4 Wag 0.605027
Datsun 710 2.801549
Hornet 4 Drive 0.259204
Hornet Sportabout -2.032508
Valiant 0.204867
Duster 360 -2.846324
Merc 240D 1.938647
Merc 230 2.300271
Merc 280 0.636986
Merc 280C 0.712003
Merc 450SE -2.168500
Merc 450SL -2.013998
Merc 450SLC -1.983030
Cadillac Fleetwood -3.540037
Lincoln Continental -3.597893
Chrysler Imperial -3.493731
Fiat 128 3.329571
Honda Civic 3.883988
Toyota Corolla 3.636227
Toyota Corona 1.962264
Dodge Challenger -2.048033
AMC Javelin -1.682576
Camaro Z28 -2.658623
Pontiac Firebird -2.354816
Fiat X1-9 3.358263
Porsche 914-2 2.440051
Lotus Europa 2.946328
Ford Pantera L -1.212566
Ferrari Dino 0.014182
Maserati Bora -2.541137
Volvo 142E 2.512210
dtype: float64
# Next we get the second principal component
(ev[1] * feat).sum(axis=1)
rownames
Mazda RX4 1.739877
Mazda RX4 Wag 1.554343
Datsun 710 -0.122632
Hornet 4 Drive -2.364265
Hornet Sportabout -0.774822
Valiant -2.778790
Duster 360 0.318210
Merc 240D -1.454239
Merc 230 -1.963602
Merc 280 -0.150858
Merc 280C -0.308009
Merc 450SE -0.698349
Merc 450SL -0.698920
Merc 450SLC -0.811307
Cadillac Fleetwood -0.841191
Lincoln Continental -0.747153
Chrysler Imperial -0.445347
Fiat 128 -0.292943
Honda Civic 0.704290
Toyota Corolla -0.276133
Toyota Corona -2.101797
Dodge Challenger -1.026281
AMC Javelin -0.913388
Camaro Z28 0.669277
Pontiac Firebird -0.899123
Fiat X1-9 -0.103399
Porsche 914-2 2.057439
Lotus Europa 1.383718
Ford Pantera L 3.498277
Ferrari Dino 3.221361
Maserati Bora 4.366990
Volvo 142E 0.258768
dtype: float64
These manually obtained PCs are identical to the ones we got earlier using pca.fit_transform(feat)
END
#PCA
from sklearn.decomposition import PCA
#TSNE
from sklearn.manifold import TSNE
#UMAP
import umap
feat
| cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|
| rownames | ||||||||||
| Mazda RX4 | -0.106668 | -0.579750 | -0.543655 | 0.576594 | -0.620167 | -0.789601 | -0.881917 | 1.208941 | 0.430331 | 0.746967 |
| Mazda RX4 Wag | -0.106668 | -0.579750 | -0.543655 | 0.576594 | -0.355382 | -0.471202 | -0.881917 | 1.208941 | 0.430331 | 0.746967 |
| Datsun 710 | -1.244457 | -1.006026 | -0.795570 | 0.481584 | -0.931678 | 0.432823 | 1.133893 | 1.208941 | 0.430331 | -1.140108 |
| Hornet 4 Drive | -0.106668 | 0.223615 | -0.543655 | -0.981576 | -0.002336 | 0.904736 | 1.133893 | -0.827170 | -0.946729 | -1.140108 |
| Hornet Sportabout | 1.031121 | 1.059772 | 0.419550 | -0.848562 | 0.231297 | -0.471202 | -0.881917 | -0.827170 | -0.946729 | -0.511083 |
| Valiant | -0.106668 | -0.046906 | -0.617748 | -1.589643 | 0.252064 | 1.348220 | 1.133893 | -0.827170 | -0.946729 | -1.140108 |
| Duster 360 | 1.031121 | 1.059772 | 1.456847 | -0.734549 | 0.366285 | -1.142114 | -0.881917 | -0.827170 | -0.946729 | 0.746967 |
| Merc 240D | -1.244457 | -0.688779 | -1.254944 | 0.177551 | -0.028296 | 1.223135 | 1.133893 | -0.827170 | 0.430331 | -0.511083 |
| Merc 230 | -1.244457 | -0.737144 | -0.765933 | 0.614599 | -0.069830 | 2.871986 | 1.133893 | -0.827170 | 0.430331 | -0.511083 |
| Merc 280 | -0.106668 | -0.517448 | -0.351014 | 0.614599 | 0.231297 | 0.256567 | 1.133893 | -0.827170 | 0.430331 | 0.746967 |
| Merc 280C | -0.106668 | -0.517448 | -0.351014 | 0.614599 | 0.231297 | 0.597708 | 1.133893 | -0.827170 | 0.430331 | 0.746967 |
| Merc 450SE | 1.031121 | 0.369533 | 0.493642 | -1.000578 | 0.885470 | -0.255145 | -0.881917 | -0.827170 | -0.946729 | 0.117942 |
| Merc 450SL | 1.031121 | 0.369533 | 0.493642 | -1.000578 | 0.532424 | -0.141432 | -0.881917 | -0.827170 | -0.946729 | 0.117942 |
| Merc 450SLC | 1.031121 | 0.369533 | 0.493642 | -1.000578 | 0.584343 | 0.085996 | -0.881917 | -0.827170 | -0.946729 | 0.117942 |
| Cadillac Fleetwood | 1.031121 | 1.977904 | 0.864106 | -1.266608 | 2.110747 | 0.074625 | -0.881917 | -0.827170 | -0.946729 | 0.746967 |
| Lincoln Continental | 1.031121 | 1.879533 | 1.012291 | -1.133593 | 2.291423 | -0.016346 | -0.881917 | -0.827170 | -0.946729 | 0.746967 |
| Chrysler Imperial | 1.031121 | 1.715580 | 1.234569 | -0.696545 | 2.209392 | -0.243774 | -0.881917 | -0.827170 | -0.946729 | 0.746967 |
| Fiat 128 | -1.244457 | -1.246216 | -1.195670 | 0.918632 | -1.056282 | 0.921793 | 1.133893 | 1.208941 | 0.430331 | -1.140108 |
| Honda Civic | -1.244457 | -1.270809 | -1.403130 | 2.533809 | -1.663729 | 0.381652 | 1.133893 | 1.208941 | 0.430331 | -0.511083 |
| Toyota Corolla | -1.244457 | -1.308518 | -1.210489 | 1.184661 | -1.435287 | 1.166278 | 1.133893 | 1.208941 | 0.430331 | -1.140108 |
| Toyota Corona | -1.244457 | -0.906835 | -0.736296 | 0.196553 | -0.781114 | 1.228820 | 1.133893 | -0.827170 | -0.946729 | -1.140108 |
| Dodge Challenger | 1.031121 | 0.715472 | 0.049086 | -1.589643 | 0.314367 | -0.556487 | -0.881917 | -0.827170 | -0.946729 | -0.511083 |
| AMC Javelin | 1.031121 | 0.600705 | 0.049086 | -0.848562 | 0.226105 | -0.312002 | -0.881917 | -0.827170 | -0.946729 | -0.511083 |
| Camaro Z28 | 1.031121 | 0.977795 | 1.456847 | 0.253559 | 0.646645 | -1.386598 | -0.881917 | -0.827170 | -0.946729 | 0.746967 |
| Pontiac Firebird | 1.031121 | 1.387676 | 0.419550 | -0.981576 | 0.651837 | -0.454145 | -0.881917 | -0.827170 | -0.946729 | -0.511083 |
| Fiat X1-9 | -1.244457 | -1.243757 | -1.195670 | 0.918632 | -1.331450 | 0.597708 | 1.133893 | 1.208941 | 0.430331 | -1.140108 |
| Porsche 914-2 | -1.244457 | -0.905195 | -0.825207 | 1.583705 | -1.118584 | -0.653144 | -0.881917 | 1.208941 | 1.807392 | -0.511083 |
| Lotus Europa | -1.244457 | -1.111775 | -0.499199 | 0.329567 | -1.769642 | -0.539430 | 1.133893 | 1.208941 | 1.807392 | -0.511083 |
| Ford Pantera L | 1.031121 | 0.985993 | 1.738399 | 1.184661 | -0.049063 | -1.903996 | -0.881917 | 1.208941 | 1.807392 | 0.746967 |
| Ferrari Dino | -0.106668 | -0.702714 | 0.419550 | 0.044536 | -0.464411 | -1.335427 | -0.881917 | 1.208941 | 1.807392 | 2.005017 |
| Maserati Bora | 1.031121 | 0.576113 | 2.790515 | -0.107481 | 0.366285 | -1.847139 | -0.881917 | 1.208941 | 1.807392 | 3.263067 |
| Volvo 142E | -1.244457 | -0.899457 | -0.558473 | 0.975638 | -0.454027 | 0.427138 | 1.133893 | 1.208941 | 0.430331 | -0.511083 |
t-SNE
t–Stochastic Neighbourhood Embedding
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=4, n_iter=4000).fit_transform(feat)
tsne
array([[ -67.28988 , -7.461225 ],
[ -70.462395 , -1.230129 ],
[-109.79255 , -26.001574 ],
[ -14.49516 , -98.97109 ],
[ 88.77131 , -10.752994 ],
[ -7.538271 , -98.85341 ],
[ 96.28523 , 32.15872 ],
[ -39.203053 , -97.86199 ],
[ -45.55487 , -103.012344 ],
[ -45.803345 , -73.82526 ],
[ -48.023323 , -80.474434 ],
[ 76.36449 , 14.991346 ],
[ 82.82964 , 8.64965 ],
[ 74.56219 , 5.692307 ],
[ 61.549232 , 66.105705 ],
[ 59.30757 , 58.038372 ],
[ 67.97727 , 59.218933 ],
[-121.32329 , -28.11285 ],
[-123.71266 , -47.980957 ],
[-125.013916 , -36.53466 ],
[ -31.122364 , -100.07239 ],
[ 101.20207 , -10.095666 ],
[ 93.759026 , -3.7495155],
[ 94.439705 , 38.97752 ],
[ 87.12706 , -18.712942 ],
[-114.96241 , -35.049763 ],
[ -80.8475 , -13.373581 ],
[ -97.24929 , -22.367165 ],
[ -50.115887 , 10.128343 ],
[ -57.95673 , 0.8419222],
[ -43.0364 , 5.2282023],
[-114.76846 , -17.610258 ]], dtype=float32)
tsne = pd.DataFrame(tsne, index = feat.index, columns= [['tsne1', 'tsne2']])
tsne
| tsne1 | tsne2 | |
|---|---|---|
| rownames | ||
| Mazda RX4 | -67.289879 | -7.461225 |
| Mazda RX4 Wag | -70.462395 | -1.230129 |
| Datsun 710 | -109.792549 | -26.001574 |
| Hornet 4 Drive | -14.495160 | -98.971092 |
| Hornet Sportabout | 88.771309 | -10.752994 |
| Valiant | -7.538271 | -98.853409 |
| Duster 360 | 96.285233 | 32.158718 |
| Merc 240D | -39.203053 | -97.861992 |
| Merc 230 | -45.554871 | -103.012344 |
| Merc 280 | -45.803345 | -73.825256 |
| Merc 280C | -48.023323 | -80.474434 |
| Merc 450SE | 76.364487 | 14.991346 |
| Merc 450SL | 82.829643 | 8.649650 |
| Merc 450SLC | 74.562187 | 5.692307 |
| Cadillac Fleetwood | 61.549232 | 66.105705 |
| Lincoln Continental | 59.307571 | 58.038372 |
| Chrysler Imperial | 67.977272 | 59.218933 |
| Fiat 128 | -121.323288 | -28.112850 |
| Honda Civic | -123.712662 | -47.980957 |
| Toyota Corolla | -125.013916 | -36.534660 |
| Toyota Corona | -31.122364 | -100.072388 |
| Dodge Challenger | 101.202072 | -10.095666 |
| AMC Javelin | 93.759026 | -3.749516 |
| Camaro Z28 | 94.439705 | 38.977520 |
| Pontiac Firebird | 87.127060 | -18.712942 |
| Fiat X1-9 | -114.962410 | -35.049763 |
| Porsche 914-2 | -80.847504 | -13.373581 |
| Lotus Europa | -97.249290 | -22.367165 |
| Ford Pantera L | -50.115887 | 10.128343 |
| Ferrari Dino | -57.956730 | 0.841922 |
| Maserati Bora | -43.036400 | 5.228202 |
| Volvo 142E | -114.768463 | -17.610258 |
plt.figure(figsize = (8,8))
x, y = tsne['tsne1'].values, tsne['tsne2'].values
ax = plt.scatter(x,y)
for i, txt in enumerate(tsne.index):
plt.annotate(txt, (x[i], y[i]), fontsize=10)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 1
----> 1 plt.figure(figsize = (8,8))
2 x, y = tsne['tsne1'].values, tsne['tsne2'].values
3 ax = plt.scatter(x,y)
NameError: name 'plt' is not defined
tsne['tsne1'].values[3]
array([-14.49516], dtype=float32)
UMAP
Uniform Manifold Approximation and Projection
import umap
reducer = umap.UMAP()
umap_df = reducer.fit_transform(feat)
umap_df
array([[7.9486165, 3.0713704],
[7.402318 , 2.874345 ],
[8.8131485, 1.4380807],
[5.5473623, 2.5566773],
[3.2108188, 3.3392804],
[5.3461323, 2.1200655],
[3.8067963, 4.5210752],
[6.58078 , 1.3951299],
[7.0341005, 1.5319571],
[6.3814726, 2.4643123],
[6.7775025, 2.2689457],
[3.0018737, 3.7647781],
[3.3977818, 3.8941634],
[4.2033854, 3.0790732],
[4.6369843, 3.9497583],
[4.3610024, 3.686902 ],
[4.0866485, 4.0934315],
[7.8208694, 1.4948332],
[8.084658 , 1.0412157],
[8.464826 , 1.220919 ],
[6.5309978, 1.658703 ],
[3.4445682, 2.9147172],
[3.6826684, 3.5611525],
[4.290335 , 4.5866804],
[3.7983255, 3.1954393],
[8.380528 , 1.812527 ],
[8.013013 , 2.5654325],
[8.112276 , 2.0220134],
[7.3071904, 3.8790686],
[7.4343815, 3.428951 ],
[6.941151 , 3.950713 ],
[8.1997385, 1.3561321]], dtype=float32)
umap_df = pd.DataFrame(umap_df, index = feat.index, columns= [['umap1', 'umap2']])
umap_df
| umap1 | umap2 | |
|---|---|---|
| rownames | ||
| Mazda RX4 | 7.948617 | 3.071370 |
| Mazda RX4 Wag | 7.402318 | 2.874345 |
| Datsun 710 | 8.813148 | 1.438081 |
| Hornet 4 Drive | 5.547362 | 2.556677 |
| Hornet Sportabout | 3.210819 | 3.339280 |
| Valiant | 5.346132 | 2.120065 |
| Duster 360 | 3.806796 | 4.521075 |
| Merc 240D | 6.580780 | 1.395130 |
| Merc 230 | 7.034101 | 1.531957 |
| Merc 280 | 6.381473 | 2.464312 |
| Merc 280C | 6.777503 | 2.268946 |
| Merc 450SE | 3.001874 | 3.764778 |
| Merc 450SL | 3.397782 | 3.894163 |
| Merc 450SLC | 4.203385 | 3.079073 |
| Cadillac Fleetwood | 4.636984 | 3.949758 |
| Lincoln Continental | 4.361002 | 3.686902 |
| Chrysler Imperial | 4.086648 | 4.093431 |
| Fiat 128 | 7.820869 | 1.494833 |
| Honda Civic | 8.084658 | 1.041216 |
| Toyota Corolla | 8.464826 | 1.220919 |
| Toyota Corona | 6.530998 | 1.658703 |
| Dodge Challenger | 3.444568 | 2.914717 |
| AMC Javelin | 3.682668 | 3.561152 |
| Camaro Z28 | 4.290335 | 4.586680 |
| Pontiac Firebird | 3.798326 | 3.195439 |
| Fiat X1-9 | 8.380528 | 1.812527 |
| Porsche 914-2 | 8.013013 | 2.565433 |
| Lotus Europa | 8.112276 | 2.022013 |
| Ford Pantera L | 7.307190 | 3.879069 |
| Ferrari Dino | 7.434381 | 3.428951 |
| Maserati Bora | 6.941151 | 3.950713 |
| Volvo 142E | 8.199739 | 1.356132 |
plt.figure(figsize = (8,8))
x, y = umap_df['umap1'].values, umap_df['umap2'].values
ax = plt.scatter(x,y)
for i, txt in enumerate(tsne.index):
plt.annotate(txt, (x[i], y[i]), fontsize=10)
